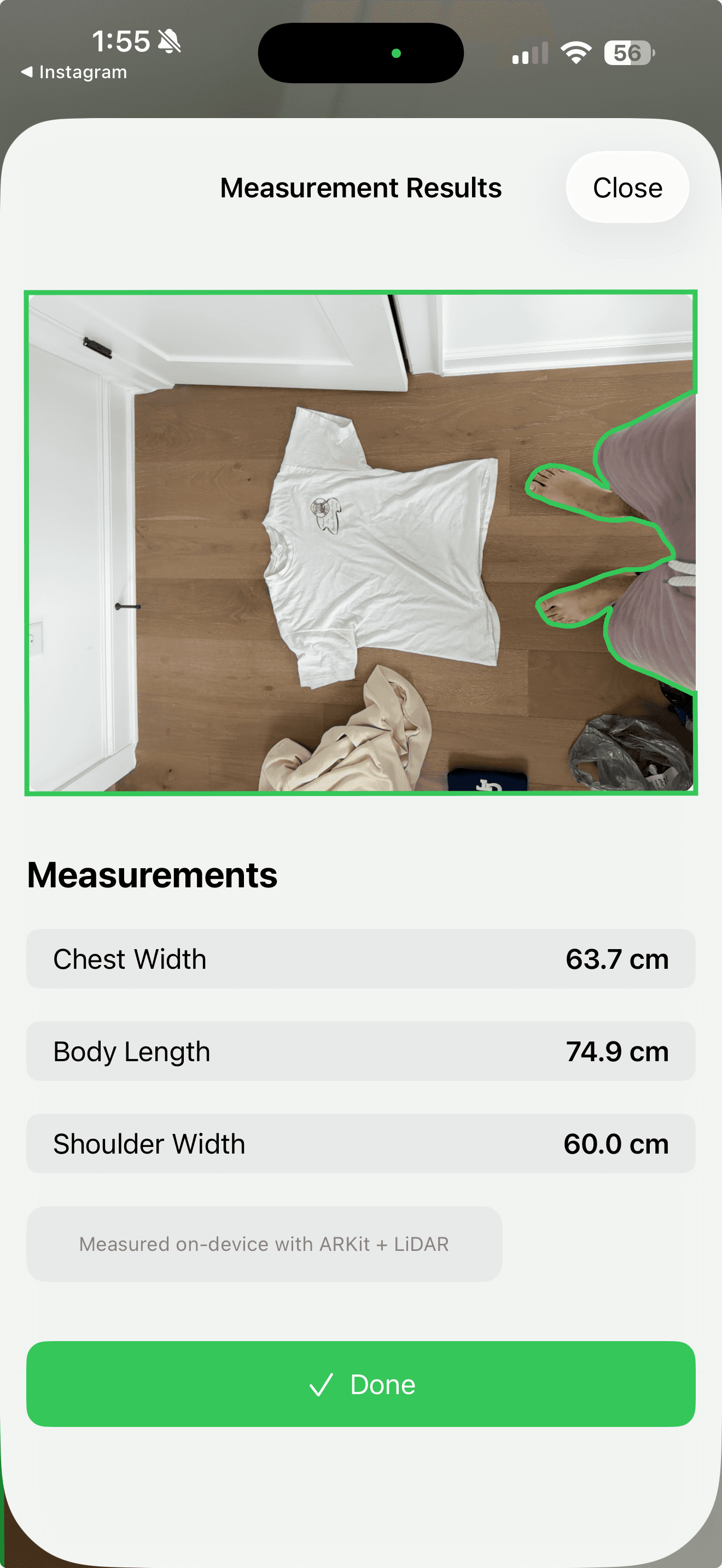
LiDAR Garment Measurement
After hitting the limits of camera-only garment detection, I built an iOS app that fuses LiDAR depth data with computer vision edge detection to capture actual clothing dimensions. The system processes spatial data through a custom pipeline combining 2D image contours with 3D point clouds, applying camera intrinsics to convert pixel coordinates into metric measurements.
Role
Solo Developer: All code, design, and product strategy
Duration
6 months
Timeline
2024-2025
The Challenge
After building a camera-only clothing detection system with YOLO, I hit a wall: computer vision could identify garments but could not measure them. I needed depth data. The iPhone Pro's LiDAR scanner provided 3D sensing, but the core problem became data fusion: how do you combine 2D edge detection (which understands shape boundaries) with 3D depth maps (which understand distance) to extract real garment dimensions like chest width, shoulder span, and inseam? Neither sensor alone was sufficient.
The Stack
The system architecture combines sensor hardware with Apple's spatial computing frameworks. Hardware capabilities provide raw data streams, while software frameworks handle coordinate transformations, scene understanding, and computational geometry.
Hardware
- iPhone 12 Pro+ LiDAR Scanner (5m range, scene depth)
- TrueDepth Camera (12MP, 60fps capture)
- IMU (6-axis gyroscope/accelerometer for transforms)
Software
- ARKit (world tracking, scene reconstruction)
- Vision Framework (VNDetectContoursRequest for edge detection)
- SceneKit (3D rendering and point cloud visualization)
- Swift SIMD (matrix calculations, camera intrinsics)
The Logic
The core measurement algorithm uses pinhole camera model projection to convert 2D garment outline coordinates into 3D camera space. This function maps edge detection points along clothing boundaries to real-world positions by applying camera intrinsics and depth data. The intrinsics matrix (fx, fy, cx, cy) encodes the camera's optical properties, allowing accurate transformation from pixel space to metric garment dimensions.
/// Project 2D outline points to 3D camera space
/// using ARKit depth data and pinhole camera model
private func projectToCameraSpace(
outlinePoints: [CGPoint],
depthMap: CVPixelBuffer,
intrinsics: simd_float3x3,
imageSize: CGSize
) -> [SIMD3<Float>] {
let fx = intrinsics.columns.0.x // focal length x
let fy = intrinsics.columns.1.y // focal length y
let cx = intrinsics.columns.2.x // principal point x
let cy = intrinsics.columns.2.y // principal point y
let depthWidth = CVPixelBufferGetWidth(depthMap)
let depthHeight = CVPixelBufferGetHeight(depthMap)
let cameraSpacePoints = outlinePoints.compactMap {
point -> SIMD3<Float>? in
let depthX = Int(Float(point.x)
* Float(depthWidth) / Float(imageSize.width))
let depthY = Int(Float(point.y)
* Float(depthHeight) / Float(imageSize.height))
guard depthX >= 0 && depthX < depthWidth
&& depthY >= 0 && depthY < depthHeight
else { return nil }
let depth = getDepth(at: depthX, depthY, from: depthMap)
guard depth > 0 && depth < 5.0 else { return nil }
// Pinhole model: pixel -> real-world coordinates
let scaledFx = fx * Float(depthWidth)
/ Float(imageSize.width)
let scaledFy = fy * Float(depthHeight)
/ Float(imageSize.height)
let scaledCx = cx * Float(depthWidth)
/ Float(imageSize.width)
let scaledCy = cy * Float(depthHeight)
/ Float(imageSize.height)
let cameraX = (Float(depthX) - scaledCx)
* depth / scaledFx
let cameraY = (Float(depthY) - scaledCy)
* depth / scaledFy
return SIMD3<Float>(cameraX, cameraY, depth)
}
return cameraSpacePoints
}The Detection Pipeline
The measurement pipeline executes as a multi-stage cascade with fallback strategies. First, I attempt hybrid CV+LiDAR detection using Vision framework contour detection to outline the garment, refined with depth clustering to isolate it from the background. If edge detection fails (wrinkled fabric, poor lighting, textured surfaces), the system falls back to pure depth-based segmentation. Each detection method feeds into the same 3D projection and measurement calculation, extracting chest width, body length, shoulder width, waist, front rise, and inseam depending on garment type.
Failure Log
Each iteration revealed fundamental limitations in on-device computer vision processing.
v1: Vision Framework Edge Detection
VNDetectContoursRequest produced 'firework patterns' with hundreds of scattered line segments radiating from fabric edges instead of clean garment outlines. The Vision framework detected every texture variation, fold, and wrinkle as a potential contour.
Implemented Douglas-Peucker algorithm to simplify contours, combined with bounding box filtering and aspect ratio validation. Added depth-based refinement that searches perpendicular to detected edges to snap contour points to the actual object surface using a 15cm depth threshold.
v2: Depth Clustering Accuracy
Pure LiDAR segmentation captured the general garment shape but missed fine details like sleeve curves and necklines. Median depth clustering created blocky, quantized outlines that lost measurement accuracy on clothing's complex, non-rigid geometry.
Built hybrid refinement pipeline: Vision framework detects initial shape, then LiDAR data refines boundary precision. For each edge point, I sample depths along the perpendicular direction and select the point closest to median object depth.
v3: On-Device Processing Limitations
iPhone Vision framework could not match the robustness of server-side OpenCV libraries. Edge detection failed on many real-world clothing scenarios: patterned fabrics, similar-colored backgrounds, wrinkled or draped garments.
Identified this as a fundamental architecture decision. The correct solution would be moving CV processing to a Python backend and keeping only LiDAR capture + 3D projection on-device. Chose not to implement due to cloud compute costs for a personal project.
The Outcome
The app runs the complete pipeline: point the camera at a garment, and it detects boundaries, projects to 3D space, and outputs measurements. In controlled conditions (solid-colored clothing, even lighting, flat surface), it produces reasonable dimensional estimates. In real-world conditions, edge detection breaks down on patterned or wrinkled fabrics. The honest conclusion: on-device Vision framework cannot match server-side OpenCV for this use case, and the correct architecture would offload CV processing to a Python backend while keeping only LiDAR capture on-device. That architectural insight, knowing where to split the pipeline between edge and cloud, was the most valuable outcome of six months of building.